UN RISCONTRO IMMEDIATO
Chiama il 3293806530

Nel mondo odierno, l'intelligenza artificiale (IA) sta rapidamente trasformando il modo in cui interagiamo con la tecnologia e affrontiamo le sfide quotidiane. Con applicazioni che spaziano dalla salute alla finanza, dalla robotica all'elaborazione del linguaggio naturale, l'IA sta diventando un elemento fondamentale in numerosi settori.
Questo glossario è stato creato per fornire una panoramica chiara e concisa dei termini e dei concetti chiave legati all'intelligenza artificiale. Che tu sia un professionista del settore, uno studente o semplicemente curioso di conoscere meglio questo affascinante campo, troverai qui definizioni utili che ti aiuteranno a navigare nel panorama dell'IA e a comprendere le sue potenzialità e sfide.
Aggiorneremo questo glossario regolarmente e speriamo sia utile.

# - A - B - C - D - E - F - G - H - I - J - K - L - M - N - O - P - Q - R - S - T - U - V - W - X - Y - Z
L'intelligenza artificiale è un campo dell'informatica dedicato alla creazione di sistemi e software capaci di simulare l'intelligenza umana. Essa comprende attività come il ragionamento, l'apprendimento e la risoluzione di problemi. Le applicazioni dell'IA spaziano dalla robotica all'elaborazione del linguaggio naturale, trasformando vari settori industriali.
Gli algoritmi evolutivi sono tecniche di ottimizzazione ispirate ai processi di selezione naturale. Utilizzano meccanismi come mutazione, crossover e selezione per trovare soluzioni ottimali a problemi complessi. Questi algoritmi sono spesso utilizzati in ingegneria, economia e scienze naturali.
Un algoritmo è un insieme di istruzioni passo-passo progettate per eseguire compiti specifici o risolvere problemi. Nel contesto dell'IA, gli algoritmi sono fondamentali per l'analisi dei dati e l'apprendimento automatico, determinando come un sistema elabora le informazioni e trae conclusioni, influenzando direttamente le sue prestazioni.
L'AI Now Institute è un centro di ricerca fondato presso la New York University, dedicato allo studio degli impatti sociali e politici dell'intelligenza artificiale. L'istituto si concentra su questioni di equità, responsabilità e governance nell'uso dell'IA.
Si riferisce a un fenomeno in cui un modello di intelligenza artificiale genera informazioni o risposte che sono completamente false, imprecise o non basate su dati reali. Queste informazioni possono sembrare plausibili e coerenti, ma non corrispondono alla realtà o ai dati di addestramento del modello.
L'analisi predittiva utilizza tecniche di data mining, statistica e apprendimento automatico per analizzare dati storici e fare previsioni su eventi futuri. Questa metodologia è applicata in vari settori, come marketing e finanza, consentendo alle aziende di prendere decisioni informate basate su tendenze e modelli identificati nei dati.
L'analisi dei sentimenti è un'applicazione dell'elaborazione del linguaggio naturale (NLP) che si occupa di identificare e classificare le emozioni espresse in un testo. Questa tecnica è utilizzata per analizzare opinioni e feedback degli utenti, migliorando la comprensione delle percezioni del pubblico.
L'apprendimento per rinforzo è un tipo di apprendimento automatico in cui un agente interagisce con un ambiente e apprende a prendere decisioni ottimali attraverso tentativi ed errori. L'agente riceve feedback sotto forma di ricompense o penalità, guidando il suo comportamento per massimizzare le ricompense nel tempo. Questa metodologia è utilizzata in applicazioni come i giochi e la robotica.
L'apprendimento supervisionato è un metodo di apprendimento automatico in cui un modello viene addestrato su un insieme di dati etichettati. Durante l'addestramento, il modello apprende a fare previsioni o classificazioni basate su esempi, migliorando la sua precisione nel tempo. È ampiamente utilizzato in applicazioni come la classificazione delle immagini.
L'apprendimento non supervisionato è una tecnica in cui l'algoritmo analizza dati non etichettati per identificare schemi e strutture senza supervisione umana. Questa metodologia è utile per scoprire relazioni nascoste nei dati e viene utilizzata in applicazioni come il clustering e l'analisi delle associazioni, facilitando l'estrazione di informazioni.
Bard è un modello di intelligenza artificiale sviluppato da Google, progettato per generare contenuti testuali e rispondere a domande in modo conversazionale. È simile a ChatGPT e si concentra sulla fornitura di informazioni utili e pertinenti agli utenti.
Il bias algoritmico è un fenomeno in cui un algoritmo produce risultati distorti a causa di pregiudizi presenti nei dati di addestramento. Questi pregiudizi possono derivare da dati non rappresentativi o da stereotipi, influenzando negativamente le decisioni automatizzate e perpetuando disuguaglianze sociali, con implicazioni etiche e legali significative.
Big Data si riferisce a grandi volumi di dati, sia strutturati che non strutturati, che possono essere analizzati per rivelare modelli, tendenze e associazioni. Questi dati provengono da diverse fonti, come social media, transazioni finanziarie, sensori IoT, registri di salute e molto altro. L'analisi dei Big Data è fondamentale in vari settori, poiché consente di prendere decisioni informate basate su informazioni dettagliate e approfondite.
ChatGPT è un modello di linguaggio sviluppato da OpenAI, progettato per generare risposte testuali coerenti e contestualmente rilevanti in conversazioni naturali. È utilizzato in vari ambiti, tra cui assistenza clienti, tutoraggio e generazione di contenuti.
Copilot è un assistente di programmazione sviluppato da GitHub in collaborazione con OpenAI. Utilizza modelli di intelligenza artificiale per suggerire codice e completare automaticamente le righe di codice durante la scrittura, migliorando l'efficienza degli sviluppatori.
DALL-E è un modello di generazione di immagini sviluppato da OpenAI, capace di creare immagini originali a partire da descrizioni testuali. Questo modello rappresenta un passo significativo nell'unione dell'elaborazione del linguaggio naturale e della generazione visiva, consentendo la creazione di opere d'arte e design innovativi.
La data augmentation è una tecnica utilizzata per aumentare la quantità e la diversità dei dati di addestramento mediante trasformazioni artificiali, come rotazioni, zoom e modifiche di luminosità. Questa pratica è particolarmente utile nel deep learning, dove grandi quantità di dati sono necessarie per addestrare modelli robusti.
Il deep learning è una sottocategoria dell'apprendimento automatico che utilizza reti neurali profonde per analizzare dati complessi. Questa tecnologia ha rivoluzionato il campo dell'IA, permettendo significativi progressi in aree come il riconoscimento delle immagini e l'elaborazione del linguaggio naturale, rendendo i sistemi più autonomi ed efficienti.
DeepSek è un modello di intelligenza artificiale specializzato nella sicurezza informatica, progettato per rilevare e prevenire minacce e attacchi informatici. Utilizza tecniche di machine learning per analizzare comportamenti sospetti e migliorare le difese dei sistemi informatici.
L'edge computing è un'architettura di rete che porta l'elaborazione dei dati più vicino alla fonte di generazione, riducendo la latenza e migliorando l'efficienza. Questa tecnologia è particolarmente utile per applicazioni di intelligenza artificiale in tempo reale, come il riconoscimento facciale e l'analisi video.
L'elaborazione del linguaggio naturale è un campo dell'IA che si occupa dell'interazione tra computer e linguaggio umano. Essa consente ai computer di comprendere, interpretare e generare testo e parlato in modo simile agli esseri umani. Le applicazioni includono chatbot, traduttori automatici e analisi del sentiment.
La Commissione Europea ha avviato iniziative per regolare l'uso dell'intelligenza artificiale nell'Unione Europea, promuovendo un approccio etico e sostenibile. Le linee guida e le normative proposte mirano a garantire che l'IA sia utilizzata in modi che rispettino i diritti fondamentali e la sicurezza dei cittadini.
Il feature engineering è il processo di selezione, modifica o creazione di variabili (o "feature") significative da utilizzare nei modelli di machine learning. Questo passaggio è cruciale per migliorare le prestazioni del modello, poiché le feature di alta qualità possono facilitare l'apprendimento e la generalizzazione.
La logica fuzzy è un approccio alla logica che consente di gestire l'incertezza e la vaghezza, utilizzando valori di verità compresi tra 0 e 1, anziché i tradizionali valori booleani di vero (1) o falso (0). Questo sistema è particolarmente utile in situazioni in cui le informazioni sono imprecise, incomplete o soggette a interpretazioni soggettive.
Gemini è un modello di intelligenza artificiale sviluppato da Google DeepMind, progettato per combinare capacità di linguaggio naturale e visione artificiale. Si propone di affrontare compiti complessi attraverso un approccio integrato, migliorando l'interazione tra testo e immagini.
Le Generative Adversarial Networks (GAN) sono un'architettura di rete neurale composta da due reti in competizione: una generativa e una discriminativa. La rete generativa crea nuovi dati simili a quelli di addestramento, mentre la rete discriminativa valuta la qualità dei dati generati. Questa interazione migliora continuamente la qualità dei dati prodotti.
La generazione di linguaggio naturale è una branca dell'elaborazione del linguaggio naturale che si concentra sulla produzione automatica di testo comprensibile e coerente. Le applicazioni includono la creazione di report, riassunti e contenuti generati automaticamente.
L'intelligenza artificiale generale rappresenta un obiettivo ambizioso nel campo dell'IA, mirato a sviluppare sistemi in grado di comprendere e apprendere qualsiasi compito intellettuale umano. A differenza dell'IA ristretta, che è specializzata in compiti specifici, l'AGI possiede versatilità e adattabilità, simile a quella degli esseri umani.

Un'interfaccia conversazionale è un sistema che consente agli utenti di interagire con computer e applicazioni utilizzando il linguaggio naturale. Le interfacce conversazionali, come chatbot e assistenti virtuali, migliorano l'esperienza utente semplificando l'accesso alle informazioni e facilitando le operazioni quotidiane attraverso interazioni intuitive.
L'intelligenza artificiale ristretta si riferisce a sistemi AI progettati per svolgere compiti specifici, come il riconoscimento vocale o la traduzione automatica. A differenza dell'Intelligenza Artificiale Generale (AGI), che mira a replicare l'intelligenza umana in modo completo, l'IA ristretta è limitata a funzioni predefinite.
Le interfacce cerebrali sono tecnologie che consentono la comunicazione diretta tra il cervello umano e i dispositivi esterni. Queste interfacce possono essere utilizzate per il controllo di protesi, dispositivi di assistenza e applicazioni di realtà virtuale, aprendo nuove possibilità nel campo della medicina e della riabilitazione.
Il Machine Learning è una branca dell'IA che utilizza algoritmi per analizzare e interpretare dati, consentendo ai sistemi di apprendere e migliorare nel tempo senza intervento umano diretto. Questa tecnologia è alla base di molte applicazioni moderne, come i motori di raccomandazione e i sistemi di riconoscimento vocale.
OpenAI è un'organizzazione di ricerca sull'intelligenza artificiale che mira a garantire che l'IA generale (AGI) avvantaggi tutta l'umanità. Fondata nel 2015, OpenAI è nota per lo sviluppo di modelli avanzati di linguaggio, come GPT-3 e GPT-4, e per il suo impegno nella ricerca etica e nella sicurezza dell'IA.
L'overfitting è una condizione in cui un modello di apprendimento automatico si adatta troppo ai dati di addestramento, risultando molto preciso su di essi ma poco efficace su nuovi dati. Questo fenomeno può essere evitato utilizzando tecniche come la regolarizzazione e la validazione incrociata, garantendo un modello più robusto.
Perplexity IA è un modello di intelligenza artificiale progettato per comprendere e generare linguaggio naturale. È noto per la sua capacità di fornire risposte informative e contestualmente rilevanti a domande poste dagli utenti, utilizzando tecniche avanzate di elaborazione del linguaggio naturale.
La privacy differenziale è una tecnica utilizzata per garantire la privacy degli individui nei dataset. Essa introduce rumore nei dati per proteggere le informazioni personali, consentendo al contempo l'analisi statistica. Questa metodologia è fondamentale per garantire la conformità alle normative sulla protezione dei dati.
Un prompt è un input fornito a un modello di intelligenza artificiale, in particolare nei sistemi di generazione di linguaggio naturale. Esso guida il modello nella produzione di output desiderato, influenzando il contenuto e lo stile della risposta generata. I prompt possono variare in complessità e lunghezza, e possono includere domande, frasi o istruzioni specifiche.
Varianti di Prompt:
Le reti neurali sono modelli computazionali ispirati alla struttura e al funzionamento del cervello umano. Composte da nodi interconnessi, queste reti elaborano informazioni e apprendono da grandi quantità di dati. Vengono utilizzate in vari ambiti, tra cui visione artificiale, traduzione automatica e analisi dei dati.
Le reti neurali a capsule sono un tipo innovativo di rete neurale progettato per migliorare la rappresentazione dei dati visivi e la loro interpretazione. Queste reti utilizzano "capsule" per mantenere le informazioni relative alle posizioni e alle orientazioni degli oggetti, migliorando così la robustezza nei confronti delle variazioni nei dati di input.
Le reti neurali convoluzionali (CNN) sono un tipo di rete neurale progettata specificamente per elaborare dati visivi. Utilizzando filtri convoluzionali, queste reti possono identificare caratteristiche e pattern nelle immagini, rendendole particolarmente efficaci per compiti come il riconoscimento facciale e la classificazione delle immagini.
Le reti neurali profonde sono una classe di modelli di deep learning che consistono in più strati di nodi. Questi modelli sono in grado di apprendere rappresentazioni complesse dai dati attraverso l'uso di strati nascosti, migliorando notevolmente le capacità di riconoscimento e classificazione.
Le reti neurali ricorrenti (RNN) sono progettate per elaborare sequenze di dati, rendendole ideali per compiti che coinvolgono dati temporali, come il riconoscimento vocale e la traduzione automatica. Grazie alla loro architettura, le RNN possono mantenere informazioni da input precedenti, migliorando la comprensione del contesto.
La robotica è l'integrazione dell'IA con la progettazione e costruzione di robot autonomi. Questi robot possono svolgere compiti fisici in ambienti variabili, come assemblaggio industriale, assistenza sanitaria e operazioni di soccorso. L'uso dell'IA nella robotica consente ai robot di adattarsi e imparare dai loro ambienti.
La simulazione Monte Carlo è una tecnica statistica utilizzata per modellare l'incertezza in processi complessi. Essa si basa su campionamenti casuali per stimare risultati e previsioni, ed è utilizzata in vari campi, tra cui finanza, ingegneria e scienze naturali.
I sistemi di raccomandazione sono algoritmi progettati per suggerire prodotti, contenuti o servizi agli utenti in base alle loro preferenze e comportamenti passati. Questi sistemi sono ampiamente utilizzati in piattaforme di e-commerce, streaming di contenuti e social media.
I sistemi esperti sono programmi informatici progettati per emulare la capacità decisionale di un esperto umano in un campo specifico. Utilizzano una base di conoscenze e regole per risolvere problemi complessi. Questi sistemi sono utilizzati in ambiti come la diagnosi medica e la consulenza finanziaria.
Il transfer learning è una tecnica che consente di trasferire conoscenze apprese da un compito a un altro, riducendo il tempo e le risorse necessarie per addestrare un nuovo modello. Questa metodologia è particolarmente utile quando i dati per un nuovo compito sono limitati, permettendo di sfruttare modelli pre-addestrati.
L'underfitting si verifica quando un modello è troppo semplice per catturare le relazioni nei dati di addestramento. Di conseguenza, il modello mostra prestazioni scarse sia sui dati di addestramento che su quelli di test. Per migliorare le prestazioni, è importante scegliere un modello adeguato e aumentare la complessità quando necessario.
La visione artificiale è un campo dell'IA che consente ai computer di interpretare e comprendere il contenuto delle immagini e dei video. Utilizzando tecniche avanzate come il riconoscimento facciale e l'analisi delle scene, la visione artificiale viene applicata in vari ambiti, dalla sicurezza alla medicina, migliorando l'automazione.
Pubblicità gratuita per il tuo sito web. Aumentare la visibilità su internet è per noi un passaggio obbligato verso un sito di successo. Da sempre realizziamo i nostri siti ottimizzandoli per il posizionamento e riproponiamo con successo le nostre tecniche anche su siti già esistenti.

Creiamo siti internet a Roma da più di 15 anni, il nostro approccio alla realizzazione di siti web è basato su un'analisi attenta delle necessità e delle esigenze, la scelta di una tecnologia adeguata, il continuo confronto con il cliente.

Sei pronto ad aggiornare e rinnovare il tuo sito? Se la risposta è no, preparati, perché dovrai farlo, e molto spesso.

Con il nuovo e normalizzato ambiente di lavoro digitale, oggi è diventata una priorità assoluta per ogni imprenditore soddisfare efficacemente le mutevoli esigenze del pubblico di destinazione, offrendo loro l'interfaccia...

Quante volte hai sentito dire “Content is King”? Probabilmente migliaia di volte sui vari blog inglesi e americani su cui blogger e aspiranti scrittori web bazzicano quotidianamente. Tuttavia, è sempre...
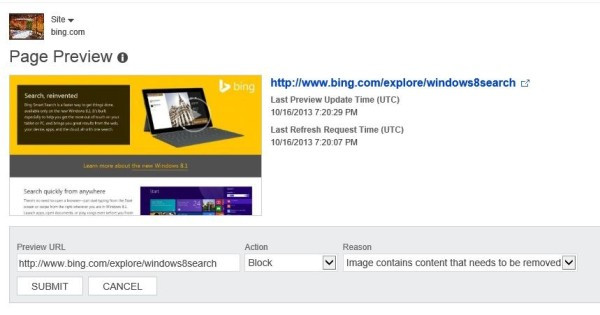
Bing torna a far parlare di sé grazie ad un nuovo tool che si aggiunge alle importanti features contenute nel suo Webmaster Tools. Se ancora non utilizzi Bing Webmaster Tool...
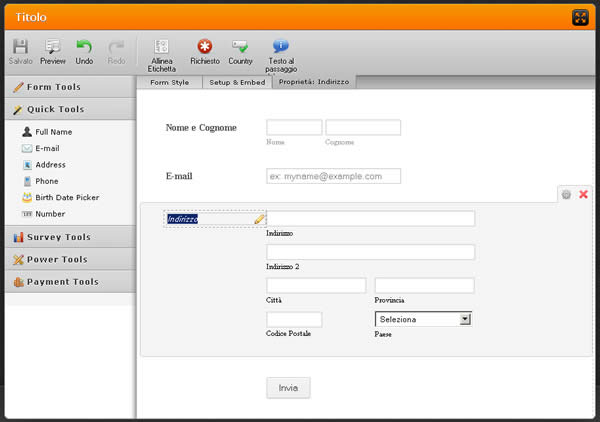
Dell'importanza e dell'utilizzo dei form in un sito web avevamo già avuto modo di parlare e quindi se sei alla ricerca di un modo semplice per costruire form d'iscrizione, sondaggi...

Google utilizza oltre 200 fattori di ranking per determinare le posizioni delle pagine dei risultati dei motori di ricerca (SERP) e regola costantemente tali fattori e la loro importanza con...


{kind=link}
{kind=link}
{kind=link}
{kind=link}